数字人文的文学之维 ——相关软件介绍与未来软件展望
数字人文(Digital Humanity)旨在以数御文,是一种交叉学科研究方法,学者用各类数字技术探索人文、社科现象,得出量化结果并将其进行可视化呈现。在世界范围内,自罗伯特·布萨(Roberto Busa)编纂托马斯·阿奎那的著作索引始,数字人文研究经历了由无到有、由少到多的演变,在英美学界相关杂志陆续诞生,相关项目层出不穷,名称和定位也经历了由人文计算(Humanities computing)到数字人文的改变。究其大略,其演进与计算机技术的发展呈正相关关系,90年代起私人电脑的广泛普及促进了其研究的丰富,近些年人工智能技术的热潮,更对其有推波助澜之势。
在中国,钱锺书先生独具只眼,最早察觉之,授意并助力在社科院启动相关研究。2000年以后,国内相关研究日渐丰富起来,相关会议陆续召开、有关公众号和杂志陆续诞生。如今,数字人文方法在历史学界、社会学界应用较广,常通过gephi、metlab等数字工具构建社会网络,从而理解历史潮流大势走向。而具体到文学研究领域,这种研究方法的应用尚且有限。
谈到数字人文方法在文学界的应用,我们不妨戏仿韦勒克的观念,将其分为外部研究与内部研究。所谓外部研究,指的是通过社会网络分析法,将作家生平、交游、空间走向等可视化,通过作家的外部数据分析,可以了解作家的接受程度,以及它与后代读者、研究者之关系。外部研究依赖于相关数据的整理工作,例如,布朗大学的“WOMAN WRITERS PROJECT”项目,致力于收集和整理收集了16世纪至19世纪中叶被忽视的女性创作或合著的作品,这类工作也被称为“数字档案馆”。
而数字人文的文学研究有一个更有魅惑力的领域——数字化“内部研究”,可以对于文本进行内部分析,不妨称之为“量化新批评”,也可对于某些词汇和语篇的历史变化进行分析,不妨称之为“量化概念史”,它最终会帮助发现一段历史的文学内部构型,与传统研究法有颇多可对话之处。毫无疑问的是,此类研究非常依赖于相关工具的成熟,本文将介绍几类国外的相关软件工具,呈现国外此类研究的样貌和走势,以期为国内相关研究提供参照。
“WordHorad”是一款文学语言分析软件,它的开发者将他们的行为称为“在解锁语言的宝藏”,的确,通过高度标记化的语料数据,以及对这些数据分布规律的发掘,我们可以获得观察这些虚构文学文本的另一只眼睛。“WordHoard”主要通过关键词提取和互相呈现的方法,对文学文本进行研究,在“WordHoard”的官方示例中,它展示了一些有趣的案例,例如“love”一词的研究,它在乔叟、莎士比亚等人那里呈现的不同拼写特点,在不同的历史时期有着不同的分布规律,通过对“love”进行统计,研究者得出了很有趣的结论:在各类叙事文本中,爱被男性说出的次数多于女性,在喜剧类文本中,被女性说出的次数则是男性的三倍,这一结果揭示了“love”的文本秘密,爱要怎么说出口?这非常值得文学史家的重视和进一步分析。
案例还提供了关于4位大作家的语言统计表——
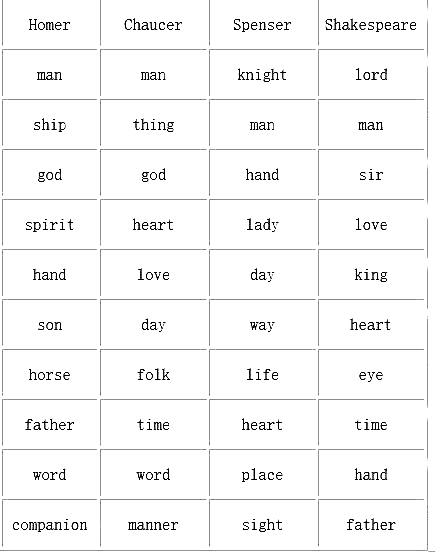
通过这样的表格可以发现,荷马、乔叟、斯宾塞、莎士比亚的风格与他们所处时代的变迁得到了一种独特的呈现,通过主题词的变迁,我们能够窥见不同时代的文学主题与不同作家的文本主题,达成对一位作家语言无意识的理解。就名词而言,在莎士比亚的所有文本中,爱是出场率第四高的名词,只有主(lord)、人(man)和先生(sir)三个词出场率高于爱,而其他三位作家所使用的最高频名词则没有爱(love),无论莎士比亚是伟大的爱情讴歌者,还是伟大的爱情质疑者,爱都是其一个重要表现和反思主题。
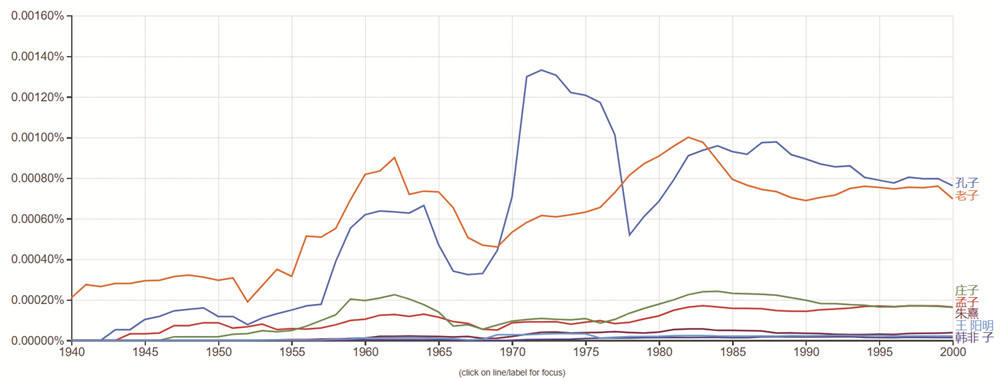
谷歌是人工智能领域的领头羊,而谷歌图书中收录的大量书籍,谷歌搜索中存在的大量网页文字数据,以及谷歌学术中的学术文字记录,都为构建这样一个庞大的语料库有所助益。它出品的在线工具“Google Ngram viewer”主要基于谷歌图书的语料库,方便展现不同语词在历史上的整体变化。通过输入想要查找的关键词,便可以看到在相关语料中,随着历史发展,相关词语的变化趋势。例如,笔者将时间限定为1940-2000年,键入孔子、孟子、老子、庄子、朱熹等中国历代思想家,可以发现,它们历年在数据库中的权重变化,这一数据显示,孔子无疑是最有热度的思想家,与学者和相关论者的思想勾连也最为密切。
再如,可以选取几位当代作家,如莫言、余华、王朔,观察自1980年代以来,在纸质书数据库中他们的权重走势。
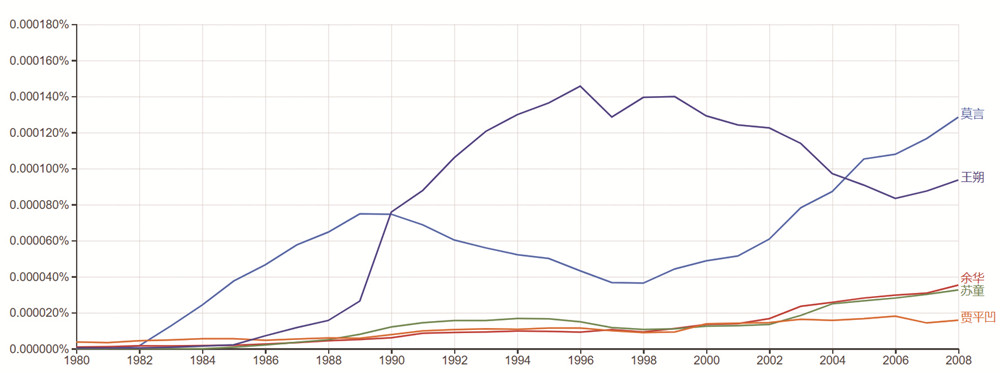
可见,这些走势也值得文学史家的注意,如果加入更多的比较维度,无疑会诞生更多有趣的研究成果。
21世纪,自人工智能技术得到了重要突破后,自然语言处理(NLP)相关技术得到了突飞猛进,如今大数据、人工智能等关键词人尽皆知,而机器翻译、语音识别、人机对话等功能也在手机端得到了广泛的应用,我们的日常生活常常与它纠缠为一体。自然语言处理技术对文学产生了一定影响,促生了引发广泛争议的“机器人写诗”现象,引得无数文学从业者困惑于诗歌的边界,也引得诸多哲学家讨论人类与机器的边界。另一方面,自然语言处理技术对文学研究也产生了很多介入的可能。
建立在自然语言处理基础上的相关研究,为文学研究提供了新的可能。“NLTK”全称为"Natural Language Toolkit",是宾夕法尼亚大学发布的自然语言处理工具,几乎是声名最为响亮的处理工具,它需要通过计算机python语言来操作和使用,该模块中包含了大量的语料资源,如《圣经》、莎士比亚的《哈姆雷特》等多部戏剧、简·奥斯丁的小说、惠特曼的诗集等,除此之外,它也包含路透社的新闻文档、美国总统的演讲集、一些电影剧本原文、网友的网络论坛聊天记录,其文本含量不可谓不丰富,源自不同历史阶段的词语储备不可谓不全面。而“NLTK”中的内置函数和功能,则有助于深度挖掘文本的表达结构,细致探索其语言模式,详尽勾勒其语言地貌。例如“similiarity”函数有助于帮助计算词汇相似度,“len”函数有助于发现文本的复杂程度,“concordance”函数有助于发现某些特定词汇的上下文等等。
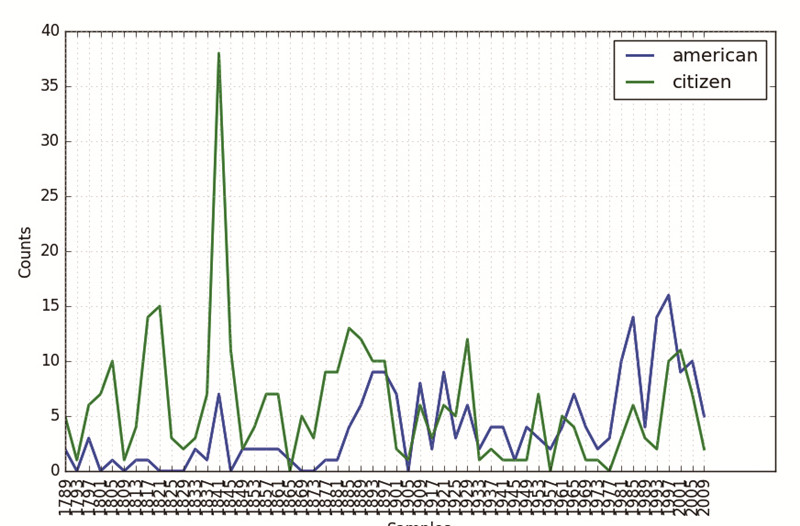
在官方相关示例中,一些独特的研究结果已经被呈现出来,例如,在不同时代的美国总统演讲中,总统想强调的重点自然不同,那么“citizen”和“american”两词的使用频率有什么变化?有关研究人员对其进行了一种可视化呈现。
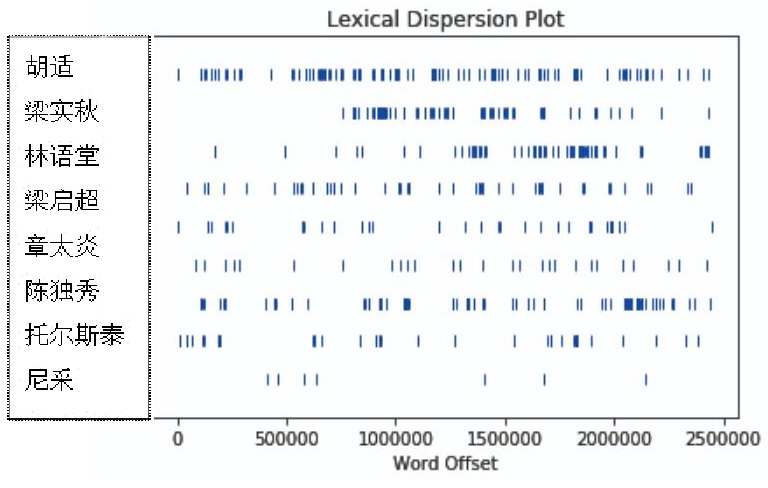
同样,也可用它对中文文本进行研究,例如,某些特定的人名在作家鲁迅的文本中的分布状况如何呢?笔者采用python中的nltk模块绘制了如下分布图。
众所周知,鲁迅先生自己的求学读书阶段,受章太炎、梁启超、托尔斯泰等影响深远,之后与梁实秋、林语堂发生过学术争论。不过,胡适成了分布最广泛的人名。
“Gephi”是一款进行网络分析的软件,自复杂科学成为学术热点,复杂网络图谱的绘制成为诸多学科中的必备技能,如传染病网络、神经网络、金融网络、物流网络等。而“Gephi”可以应用于文学内部研究领域,绘制一部作品内部的语言网络。例如,通过对鲁迅作品中形容词进行统计分析,可以发现其内部语言网络。
不过,目前这些软件大部分集中于英文处理,基于相对完备的英文语料库,同样也基于西方世界,尤其是美国在计算机科学方面的领军地位,和西方世界人文社科学界的前沿视角。而中文语料库以及建立在其之上的研究板块,呈现出一种缺失。近些年,作家走走的团队已经致力于开发中文文本分析的软件,对文学杂志《收获》中的文学作品和网络文学进行分析,并取得了可观的成果。不过,更值得期待的是这一领域的成果日益丰富,观点百花齐放,为传统文学史与文论研究提供了另一种参照。
类似的中文文学文本分析工具还有待丰富。不过,如今自然语言处理技术的发展,人工智能的发展,以及通用人工智能(AGI)的畅想,为这种丰富提供了一种可能,笔者对这样的一款文学通用软件做出如下畅想——
首先,它能够进行基本的词频分析,和建立在词频以及权重分析上的词语分布研究,通过它,我们可以发现不同作家和不同时代的文本差异。例如,20世纪20年代中国文学的高频词是哪些?与30年代有何不同?京派文学与海派文学可以通过这种方式得到量化的区分吗?唐宋之争中的唐诗宋词,是否存在文本关键词分布的明显差异?
其次,建立不同的词典库,针对不同词性的分布进行具体分析,这些包含基本的动词、形容词、名词等,也可以通过专门词典的建立,分析某一类(如文论类,哲学类词)的分布。例如,鲁迅先生最爱用哪些动词?美学家朱光潜最喜爱引用哪些人名?当代文学理论和文学史类教材里哪些概念出现频率最高?这些都是饶有趣味的文体。
再次,通过基于lstm原理和tensorflow的操作方式,通过情感计算来探索文本的情感分布奥秘,发现文本的情感曲线和走势图,窥探不同作家的情绪世界,不同批评家的情感风格,以及某一时代的读者群落的精神风貌。韩愈散文的情感走向与南朝骈文有何不同?网络玄幻小说的情感走向较之传统武侠小说有何变化?
最后,在目前技术达不到的一些方面,还可做出更丰富的畅想——一款未来软件,或未来编程语言的模块,也能总结叙事类型,比较文本语言差异等,让传统学者的文学分析功力更有效地施展,让计算机的研究结果和批评家的研究成果可以达成互为补充的效果。
那么,能否实现一个未来的中文文学研究软件呢?它的可行性和可能性边界在何方呢?事实上,除了技术的进步,它还需要有庞大的文学语料库资源,包含纸质文学与网络文学作品,包含纸质出版物的文学评论与网友评论,在这一方面,纸质文本高准确率的数字化处理需要完成,版权也成为了某种限制。也许,全知全能型的研究软件短期还不能实现,或许我们也不期待它出现。而且,在重新审视中国文学与文论变迁上,辅助性较强的软件绝对可以发挥非常重要的作用。较之于莫莱蒂的远读法,新的细读法仍有其价值,不过它是一种新的细读法,不妨称之为数字细读法或量化细读法,这样的读法在国内刚刚起步,这样的数据库等待建立,而这样一款研究软件则充满诱惑。


